 超算云
超算云 AI智算云
AI智算云在北京超算V100-32G显卡上跑WRF是一种怎样的体验?
在北京超算GPU上跑WRF是一种怎
1WRF on GPU?YES!
WRF是在美国国家大气研究中心(NCAR)开发的天气研究和预报模型。它被162个国家的36000多个注册用户广泛使用。WRF具有多个动态核心,支持大规模并行计算,且系统可扩展性很强。WRF 适用于从米到数千公里的广泛应用。它是气象学科中最为广泛使用的数值模式之一。
熟悉WRF模式的小伙伴都知道,WRF是在CPU上运行的。而随着高性能计算技术,特别是使用图形处理器(GPU)等硬件进行大规模并行计算的技术正在日渐成熟,并在人工智能等领域不断长足发展。
那么,既然WRF如此适合大规模并行计算,那么,我们可以在GPU上运行WRF,以达到减低成本、增加效率的效果吗?答案当然是YES。
2AceCast: WRF的GPU版本
AceCast是美国TempoQuest (TQI)公司开发的软件产品。其前身为英伟达公司支持开发的WRF-G。它由GPU提供支持,可以加速WRF模型。AceCAST 是五年来一丝不苟的研究和开发的产物,它使得 WRF 用户能够利用 GPU 硬件与传统 CPU 计算的高度并行性来保证优化性能。AceCAST 包含了大量重构的通用 WRF 物理、动力学模块和namelist,它使用了NVIDIA CUDA 或 OpenACC GPU编程技术,允许广大用户几乎不需要改变任何配置,就能将AceCAST作为现有WRF的平替,并加以使用。
GPU通过使用具有高速计算速度和非常高的内存带宽的多线程、多核处理器来实现异常的加速。通用超级计算、高并行性、高内存带宽、低成本和紧凑体积的综合特性使得基于 gpu 的系统成为由普通 CPU 集群组成的大规模并行处理机/计算机系统的一个有吸引力的替代品。基于 GPU 开发的WRF 是目前世界上最快、分辨率最高的天气预报模型。
TempoQuest 通过利用GPU加速 WRF 模型解决了这个问题。与标准的计算方法相比,AceCAST 是目前世界上最快和分辨率最高的天气预报模型。通过 AceCAST 运行 WRF,使用户能够以更高的分辨率、更低的成本和更深的洞察力运行预测和研究模拟,并加速解决时间流程。AceCAST 的能力为气象学家和最终用户提供了 WRF 产品,这些产品能够提高对全球气象模型无法识别或在低分辨率情况下无法识别的局部天气现象的认识。计算性能的提高使得高分辨率的确定性和概率性预报成为可能,而且比在中央处理器上运行 WRF 成本更低,预报模拟加速度一致地将预报处理速度提高了5倍。
3AceCast实战测试
为了准确评估比较WRF在GPU和CPU上的运行速度,我和北京超算团队一起,使用北京超算提供的8卡V100-32G显卡资源,对一个800×600×33,单层嵌套的个例进行模拟。分别进行了1卡、2卡、4卡和8卡四个实验,主要计算其运行效率。实验结果如下:
GPU个数 | 运行时间 |
1 | 约21分钟 |
2 | 约12分钟 |
4 | 约7分20秒 |
8 | 约5分钟 |
4对比:CPU上运行WRF的效率
CPU节点数 | 运行时间 |
1 | 30分51秒 |
2 | 16分9秒 |
4 | 9分33秒 |
8 | 6分31秒 |
5对比:性能和价格
在北京超算上,一张V100-32G显卡的价格约为5元/小时(价格根据用户合同和使用时间等因素不同,会有所波动,下同。);一个CPU核心的价格约为0.1元/小时。由此可以估算出,这次试验的消费金额(单精度CPU节点以40%提速预计,未进行实地实验):
设备 | 运行时间 | 理论价格(元) |
CPU*1节点 | 30分51秒 | 3.29 |
CPU*2节点 | 16分9秒 | 3.44 |
CPU*4节点 | 9分33秒 | 4.07 |
CPU*8节点 | 6分31秒 | 5.56 |
单精度CPU*1节点 | 22分2秒 | 2.35 |
单精度CPU*2节点 | 11分32秒 | 2.46 |
单精度CPU*4节点 | 6分49秒 | 2.91 |
单精度CPU*8节点 | 4分39秒 | 3.97 |
GPU*1卡 | 21分钟 | 1.75 |
GPU*2卡 | 12分钟 | 2.00 |
GPU*4卡 | 7分20秒 | 2.44 |
GPU*8卡 | 5分钟 | 3.33 |
6总结与讨论
由表格我们可以得出以下结论:
使用单卡GPU的性价比最高,约比CPU上单精度计算便宜25%,比传统的双精度便宜50%左右;
就速度而言,在CPU(单精度)使用不超过2个节点时,使用GPU也比CPU要快(不考虑辐射参数化方案的影响的前提下;考虑的话,相信速度提升会更明显)。考虑到我们一般模拟任务不太会超过800×600×33,可见使用GPU,不管是时间还是金钱成本上,肯定都是优于CPU的;
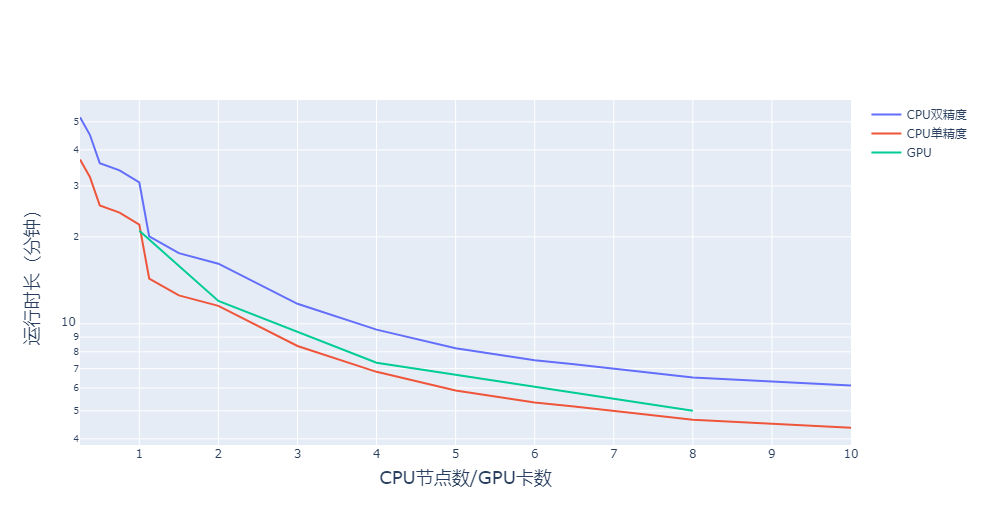
GPU运行速度随着卡数的上升,并非是线性提高的。具体如下图所示:
本次采用的GPU为V100-32G。其单精度浮点运算性能14TFlops;而如果我们采用单精度浮点运算性能更高、价格却更加便宜的3090显卡(35.7TFlpos),相信GPU的优势可以变得更为明显。
总结一句话:要是WRF规模不太大,直接上单卡3090!性价比最高,最省时间!
7参考文献
FV3 (2017): www.gfdl.noaa.gov/fv3/fv3-performance
Váňa et al (2017) "Single Precision in Weather Forecasting Models: An
Evaluation with the IFS" Mon. Wea. Rev., Vol. 145, No. 2. (7 December 2016),
pp. 495-502, doi:10.1175/mwr-d-16-0228.
北京超算GPU算力资源
A100V1003090A10T4国产DCU等多种型号;提供云主机、集群、裸金属云服务等多种算力平台;支持多机多卡,满足训练、推理、科学计算等多计算场景需求。让GPU算力触手可及,省事省心,高效专注科研!
扫码免费领取2000核时或200元卡时计算资源!







