 超算云
超算云 AI智算云
AI智算云行业应用|用北京超算跑大型结构动力学仿真是种什么样的体验?
测评内容说明
最近由于大型仿真分析项目需求,有幸接触到了北京超级云计算中心(如下简称北京超算),同时也体验到了超算中心对于低成本拓展仿真分析规模的系列优势。
为了帮助大家更好地了解和使用超算中心,笔者将通过系列文章对超算中心的使用以及计算性能进行测评,本文内容为ANSYS软件使用测试,测试参数如下:
超算中心 | 北京超级云计算中心 |
CPU类型 | AMD |
核心数 | 64 |
主频 | 2.35GHz |
内存 | 256G |
磁盘空间 | 500G |
测试软件 | ANSYS WorkBench 2021R1 |
北京超级云计算中心可根据使用者需求提供不同型号CPU,核心数,内存大小以及磁盘空间,上述数据仅为本次测评使用参数。
相比于零件分析,大型装配体除了网格数量较多外,还包含大量的连接关系,绑定接触以及混合单元类型,因此一般情况下计算量相比于同等节点数量的零件大,体现的计算问题也更加全面。
为了更加真实地测试超算平台的使用性能,文章选取如下大型装配体:

模型来源于GrabCAD官网
根据实际测试,该模型进行高阶实体单元划分,最低节点数量50万,但是通常装配体由于计算精度要求会比该数量多,因此本文按照100万节点数量进行测试,具体有限元模型如下:

整体有限元模型使用高阶四面体单元处理,节点数量107万,MPC绑定接触对200+。
考虑到同等节点数量下,动力学分析比静力学分析计算量和计算时间要大得多,因此本文使用动力学分析的模态分析模块进行测试,算法选择Block Lanczos,提取模态阶数100阶。
注意
该模型分析已经在本地64G电脑上经过测试,由于内存需求远远超出电脑性能无法计算,因此只能借助超算平台进行计算。
平台使用流程
Step1:本地准备工作
由于超算中心计费是从创建分析项目开始,而不是求解计算,因此作为分析中最为耗时的前处理工作,一般是在本地电脑完成,整体模型装配好后导入超算中心进行调试和分析:
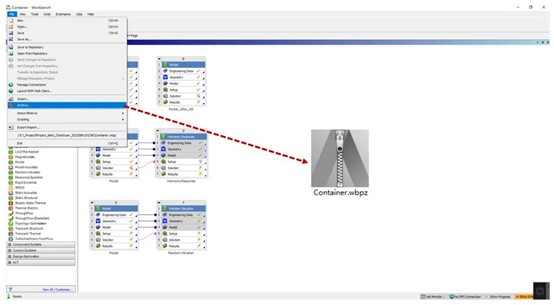
对于ANSYS WorkBench来说,使用Archive功能导出求解文件的压缩包较为推荐,对于Abaqus直接导出对应版本的.inp文件,对于HyperWorks导出对应版本的.fem文件,这些求解文件在超算平台中均能正常读取。
Step2:求解文件上传
对于每个用户,超算中心会单独开辟一块磁盘空间供数据存储,类似于个人电脑上的一个盘,一般最低有500G,个人可以对空间中的数据进行常规编辑和清理工作,我们的计算文件也是存储在该空间下。
为了使得超算平台能够读取计算文件,需要登录超算平台,将求解文件通过指定软件上传到提供的存储空间中:
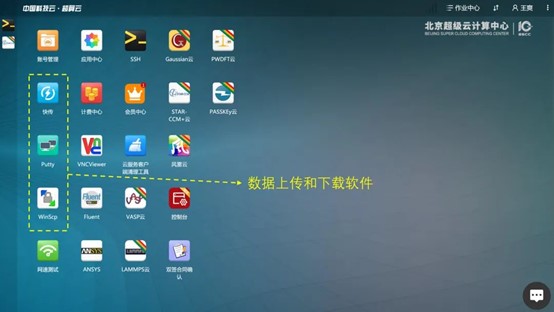
超算中心界面
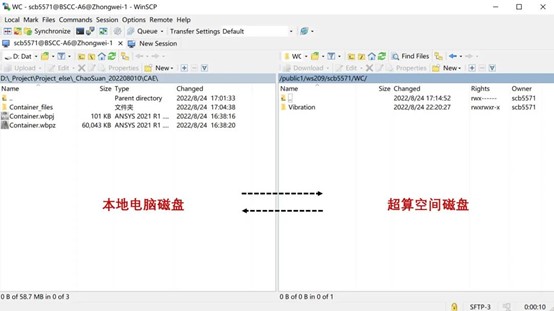
磁盘文件交互
由于直接拖动就可以实现本地电脑和超算平台的数据交换,传输速度也能保证在3~5Mb/s以上,因此使用起来相对也比较方便。
Step3:创建分析项目
本地数据导入完成之后,通过超算中心桌面的VNC可以创建分析项目,也可以直接通过桌面上的ANSYS软件直接启动:
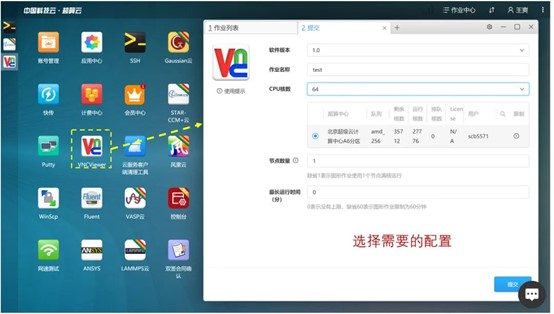
根据计算需求,我们选择amd_256队列(代表CPU为AMD,最大使用内存256G),核心数选择64(可以根据自己需求使用更多核心),提交之后,等待连接成功,即可进入可视化界面。

应用窗口
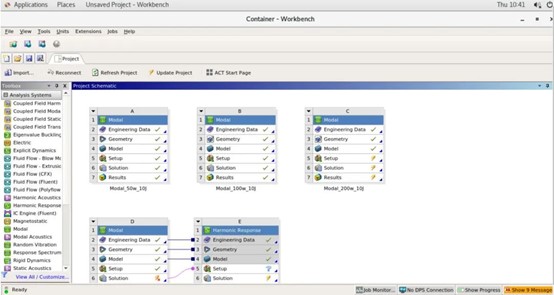
WorkBench界面
Step4:调试和求解
由于超算中心提供了可视化界面,因此调试和求解的部分和我们正常操作没有任何区别,这里直接使用60核进行计算:
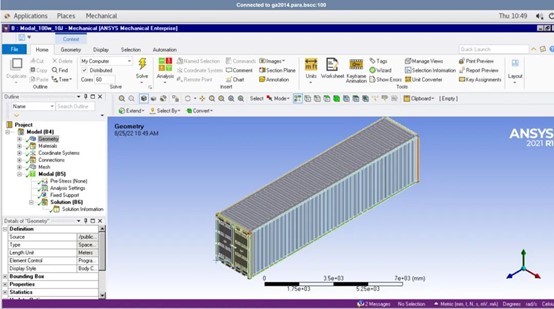
ANSYS WorkBench后台统计的计算时间和内存占用情况如下:
统计内容 | 具体数据 |
内存占用 | 157GB |
计算时间 | 27分52秒 |
结果文件 | 2.6GB |
对于一个大型装配体的动力学计算来说,计算速度还是比较满意的。
Step5:后台数据监测
在计算过程中,可以通过桌面软件SSH,输入指定的简易代码,方便地查询到调用核心以及内存空间的使用情况,如图所示:
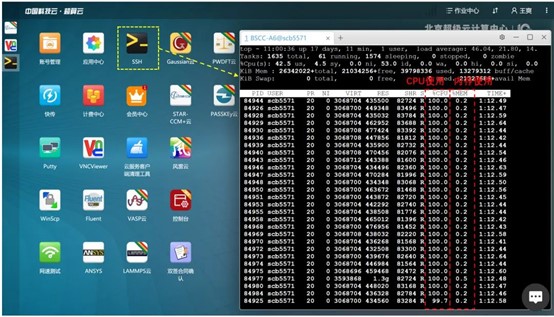
测评结果
本次使用超算测评,大致总结如下体验:
①内存足够大,目前了解到最大内存可以支持2T,本次使用的测试模型需要占用157GB内存,对于大部分本地电脑无法处理,并且个人配置到这么高的内存空间成本非常高
②核心数足够多,虽然在结构分析中,超过16核加速效果已经不太明显,但是对于流体等分析来说,核心数对计算速度的改善还是非常可喜
③流程足够完善,早期听到超算中心我都是有些畏惧的,感觉这东西应该很复杂,需要传输各种文件,输入各种求解命令调用,但是这次使用后发现,现在平台从可视化界面,文件传输,后台查询等都做得很完善,给人的感觉就是远程调用一台高性能电脑
④服务足够到位,开始使用超算中心确实会遇到各种疑问,但是配备的技术支持微信群能快速响应并给出解决方案,体验感比较好。
以上便是本次云计算中心的测评内容,整体体验感比较舒服,当然之后会针对具体分析问题进行求解速度和内存占用的测评。






